<?php
//...
class AdsController extends AppController {
public function add() {
if ($this->request->is('post')) {
if ($this->Ad->save($this->request->data)) {
$this->Session->setFlash('The ad was saved!');
$inserted_id = $this->Ad->id;
$this->redirect(array('action' => 'view', $inserted_id ));
} else {
$this->Session->setFlash('The ad could not be saved!');
}
}
// ...
}
// ...
public function view($id) {
$this->Ad->id = $id;
$this->set('ad', $this->Ad->read());
}
}
The key line is the redirect. It took me a while to figure out how could I pass the just inserted id to the view page.
Tuesday, December 18, 2012
CakePHP: Save and Show
In this small code snippet I show how to store some formulary data corresponding to an ad, and after saving redirect to the page to show the stored values.
Friday, November 23, 2012
Android: Checking WiFi Connection
To be able to check WiFi connection in an Android application you first need to set the proper permission in the Android manifest:
<manifest xmlns:android="http://schemas.android.com/apk/res/android"
package="com.example.mytoolbox"
android:versionCode="1"
android:versionName="1.0" >
<uses-sdk
android:minSdkVersion="9"
android:targetSdkVersion="15" />
<uses-permission android:name="android.permission.ACCESS_NETWORK_STATE" />
...
</manifest>
Here's a code to check the WiFi. If it's not on it shows an alert message indicating connection is required and then it finishes the application:
private void checkWiFiConnectivity() {
ConnectivityManager connMan = (ConnectivityManager)
getSystemService(Context.CONNECTIVITY_SERVICE);
boolean wifiIsOn = connMan.getNetworkInfo(ConnectivityManager.TYPE_WIFI)
.isConnectedOrConnecting();
Log.d("GABO", "WiFi is : " + wifiIsOn);
if(!wifiIsOn) {
finishApplication();
}
}
private void finishApplication() {
AlertDialog.Builder builder = new AlertDialog.Builder(MainActivity.this);
builder.setMessage("You need WiFi connection to access this App!");
builder.setCancelable(false);
builder.setPositiveButton("OK", new DialogInterface.OnClickListener() {
@Override
public void onClick(DialogInterface dialog, int which) {
MainActivity.this.finish();
}
});
AlertDialog alert = builder.create();
alert.show();
}
Thursday, November 22, 2012
JavaScript: Copy & Highlight
As part of my discipline for documenting those functionalities that make me suffer and sweat, I want to leave this short code exemplifying how to make a copy & paste of an element of the DOM, at the same time that it highlights the element.
For the copy part I used a popular library that uses a Flash file as the executor of the operation: ZeroClipboard. The copy operation is not a standard capability of all browsers. That's whay a Flash file is requried. For the highlighting I found a code that works properly in the main browsers (IE, FF, Safari & Chrome). These are the functions in the below code: "getTextNodesIn" and "setSelectionRange". The entire code below allows the user to click in the text for automatically make a copy to the clipboard, and then show copied text as an alert message. At the end it highlights the text.
For the copy part I used a popular library that uses a Flash file as the executor of the operation: ZeroClipboard. The copy operation is not a standard capability of all browsers. That's whay a Flash file is requried. For the highlighting I found a code that works properly in the main browsers (IE, FF, Safari & Chrome). These are the functions in the below code: "getTextNodesIn" and "setSelectionRange". The entire code below allows the user to click in the text for automatically make a copy to the clipboard, and then show copied text as an alert message. At the end it highlights the text.
<html>
<head>
<script type="text/javascript" src="ZeroClipboard.min.js"></script>
<script type="text/javascript">
function getTextNodesIn(node) {
var textNodes = [];
if (node.nodeType == 3) {
textNodes.push(node);
} else {
var children = node.childNodes;
for (var i = 0, len = children.length; i < len; ++i) {
textNodes.push.apply(textNodes, getTextNodesIn(children[i]));
}
}
return textNodes;
}
function setSelectionRange(el, start, end) {
if (document.createRange && window.getSelection) {
var range = document.createRange();
range.selectNodeContents(el);
var textNodes = getTextNodesIn(el);
var foundStart = false;
var charCount = 0, endCharCount;
for (var i = 0, textNode; textNode = textNodes[i++]; ) {
endCharCount = charCount + textNode.length;
if (!foundStart && start >= charCount
&& (start < endCharCount ||
(start == endCharCount && i < textNodes.length))) {
range.setStart(textNode, start - charCount);
foundStart = true;
}
if (foundStart && end <= endCharCount) {
range.setEnd(textNode, end - charCount);
break;
}
charCount = endCharCount;
}
var sel = window.getSelection();
sel.removeAllRanges();
sel.addRange(range);
} else if (document.selection && document.body.createTextRange) {
var textRange = document.body.createTextRange();
textRange.moveToElementText(el);
textRange.collapse(true);
textRange.moveEnd("character", end);
textRange.moveStart("character", start);
textRange.select();
}
}
function highlight() {
var element = document.getElementById("span_id");
setSelectionRange(element, 0, element.innerHTML.length);
alert("copied!");
}
</script>
</head>
<body>
<span id="span_id">Copy Me!</span>
<script>
ZeroClipboard.setMoviePath( 'ZeroClipboard.swf' );
var clip = new ZeroClipboard.Client();
var element = document.getElementById("span_id");
clip.setText( element.innerHTML )
clip.glue( 'span_id' );
clip.addEventListener( 'onMouseUp', highlight );
</script>
</html>
</body>

Sunday, November 18, 2012
MongoDB under its proper context
A couple of weeks ago I attended to a CRJUG speak organized by the folks of BodyBuilding.com. In this time they gave us an introduction to the world of MongoDB, a non-sql database engine that they use in their site. I really enjoyed the loose style of the speakers. A “For programmers-by-programmers” approach. They showed us the differences of this paradigm with the traditional relational paradigm. I think they were very transparent from the beginning stating that they didn’t come in an “evangelistic mission”. They know as many do that this approach serves specific purposes. It doesn’t substitute the secure, transaction-safe, full referential integrity relational databases. Like in many things in computer science where there is this constant battle to try to balance all key aspects of a system: security, robustness, speed, etc, databases as well do not escape from this challenge.
I’m emphasizing this point for something that I found interesting during the presentation. Since there was openness at all time for questions and comments, some participants in various occasions insisted in compare this solution with standard relational database, which in principle it’s fine to point out why it’s done differently, but what I find interesting is that I detected some sort of skepticism while discussing the topics, like “I cannot believe the standard rules are being broken”. This was not said literally, I’m just describing my perception from their feedback. For example one participant commented that Oracle has some ways to attack similar problems. In other occasion there was brief argumentation of why MongoDB didn’t continue with a typical SQL language instead of using a very different query language, because after all, it would be easier for the entire developer’s community who already know SQL.
This is interesting, but not surprising. Relational databases had been with us for more than 40 years. They are older than a lot of us. That’s why a lot of people find it a little difficult to believe that a new approach is required. Maybe it’s similar like if there was new programming language selling the idea that OOP should be dismissed. In my humble opinion I believe new paradigms experimentation is always required in order for innovation to appear. I also think we don’t have drive ourselves in a “Hispster” fashion, looking for the newest technologies and then labeling the other ones as the old fashion ones. Relational databases are too long to be entering the retiring cycle, but still we need to start considering the new guys entering the scene.
In this very funny video we see this point shown, where many people are too fast in dismissing the old technologies without having solid argumentation; just playing hipster with technology. I don’t think the video is a criticism to MongoDB, but a criticism to people who do not know the proper context of certain technologies. If you have a small start-up, you should not be worrying in the short term about scaling and use a non-sql database. Over architecting an application can cause more problems than it solves. But that’s another discussion I would like also to write about it in another moment.
Wednesday, November 7, 2012
Simple code for finding missing alphabet letters in a sentence
I consider no code is trash even if it's too trivial. And I also hate the sensation of knowing I code something similar before, but have to repeat the coding because I didn't save it. Some time ago I had to code a solution for a simple problem as part of the recruiting process in a company. The problem to solve is to find the missing letters of the alphabet in a given sentence.
import java.util.HashSet;
import java.util.Set;
/**
* Test code to find missing letters of the alphabet from a String sentence.
* @author gabriel.solano
*
*/
public class MissingLetters {
private final int ASCII_CODE_FOR_LETTER_A = 97;
private final int ASCII_CODE_FOR_LETTER_Z = 122;
/**
* Gets the missing letters of a sentence in lower case.
* @param sentence
* @return String having all the letters that the sentence is missing from the alphabet.
*/
public String getMissingLetters(String sentence){
/*
* 1. Let's populate a set with the unique characters of the sentence.
* This approach avoids having two nested for's in the code (better performance).
*/
Set<Integer> uniqueASCIICodes = new HashSet<Integer>();
for (char character : sentence.toLowerCase().toCharArray() ) {
if (character >= ASCII_CODE_FOR_LETTER_A
&& character <= ASCII_CODE_FOR_LETTER_Z) { // Range of lower case letters.
uniqueASCIICodes.add((int)character);
if (uniqueASCIICodes.size() == 26) {
break; // Sentence already covered all letter from the alphabet.
}
}
}
/*
* 2. Move in the range of ascii codes of lower case alphabet
* and check if letter was present in sentence.
*/
StringBuilder misingLettersBuilder = new StringBuilder();
for (int i=ASCII_CODE_FOR_LETTER_A; i <= ASCII_CODE_FOR_LETTER_Z; i++) {
if (!uniqueASCIICodes.contains(i)) {
misingLettersBuilder.append((char)i);
}
}
return misingLettersBuilder.toString();
}
public static void main(String[] args) {
String case1 = "A quick brown fox jumps over the lazy dog";
String case2 = "bjkmqz";
String case3 = "cfjkpquvwxz";
String case4 = "";
MissingLetters missingLetters = new MissingLetters();
System.out.println("Missing letters for[" + case1 + "]: " +
missingLetters.getMissingLetters(case1));
System.out.println("Missing letters for[" + case2 + "]: " +
missingLetters.getMissingLetters(case2));
System.out.println("Missing letters for[" + case3 + "]: " +
missingLetters.getMissingLetters(case3));
System.out.println("Missing letters for[" + case4 + "]: " +
missingLetters.getMissingLetters(case4));
}
}
This will be the program output:
Missing letters for[A quick brown fox jumps over the lazy dog]: Missing letters for[bjkmqz]: acdefghilnoprstuvwxy Missing letters for[cfjkpquvwxz]: abdeghilmnorsty Missing letters for[]: abcdefghijklmnopqrstuvwxyz
7 basic tips to be a Pro Code Surfer with Eclipse
In this short article I want to show to the “newbies” of Eclipse some basic tips that are essential in big projects when we need to “surf” trough a lot of “waves” of code.
1. Look for resources
Forget that old folder/package hierarchy navigation style. If you know the name of the resource you are looking for, or at least part of it, use the resource opener feature (CTRL + SHIFT + “R”). You can use wild cards in case you forgot the full name.

2. Open type.
Want to go beyond the frontiers of your (*.java)'s? If you want to open a file contained in a JAR, a .class for example, then the open type feature lets you do that (CTRL + SHIFT + “T”). Of course you can only open a .class as long as you have the .java in the same jar or you had configured a Java decompiler (out of the scope for this day).

3. Class/Object code appearances
Sometimes you want to see in a big scale where are the appearances of a certain class or object. By simply double clicking the class or object the IDE will highlight all the appearances making it easier for us instead of going line by line or using the find command.

4. If inside a class there is a reference of another one, just press and hold CONTROL key, the class will be underlined letting you know that you can click it and then travel to that one.
5. References
Want to know how popular is your class or method? Use the references opener to find it out. Select your class or method, right mouse click > References > [Workspace | Project | ...]
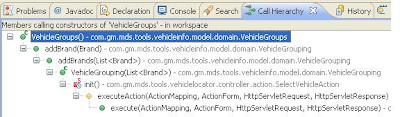
6. Call Hierarchy
A long line between your method and its originator? Do not try to be a paleontologist, use the call hierarchy to find its origins. Right click on your method > Open Call Hierarchy (or CTRL + SHIFT + “H”) and “voila”.
7. File Search
When the thing your are looking for is pretty much hidden in your code, including XML, JavaScript, JSP, *, then what you need is a file search: CTRL + “H”

1. Look for resources
Forget that old folder/package hierarchy navigation style. If you know the name of the resource you are looking for, or at least part of it, use the resource opener feature (CTRL + SHIFT + “R”). You can use wild cards in case you forgot the full name.

2. Open type.
Want to go beyond the frontiers of your (*.java)'s? If you want to open a file contained in a JAR, a .class for example, then the open type feature lets you do that (CTRL + SHIFT + “T”). Of course you can only open a .class as long as you have the .java in the same jar or you had configured a Java decompiler (out of the scope for this day).

3. Class/Object code appearances
Sometimes you want to see in a big scale where are the appearances of a certain class or object. By simply double clicking the class or object the IDE will highlight all the appearances making it easier for us instead of going line by line or using the find command.

4. If inside a class there is a reference of another one, just press and hold CONTROL key, the class will be underlined letting you know that you can click it and then travel to that one.

5. References
Want to know how popular is your class or method? Use the references opener to find it out. Select your class or method, right mouse click > References > [Workspace | Project | ...]
6. Call Hierarchy
A long line between your method and its originator? Do not try to be a paleontologist, use the call hierarchy to find its origins. Right click on your method > Open Call Hierarchy (or CTRL + SHIFT + “H”) and “voila”.
7. File Search
When the thing your are looking for is pretty much hidden in your code, including XML, JavaScript, JSP, *, then what you need is a file search: CTRL + “H”

Tuesday, November 6, 2012
Tres Amigos of Persistance (DAO - DAOFactory - BO)
Nowadays, even with all the good accumulated knowledge we have in design patterns, software engineers still tend to program classes where business logic is mixed with persistence logic. Even some experienced developers omit this important aspect of software architecture maybe for lack of knowledge, or just for the rush to start programming quickly. I consider the last reason is the most common of all.
Now why should we bother too much about this separation? well, the idea is not to develop a case for what is basic in software architecture:
multi-tier(layer) programming, but to help with some useful patterns to accomplish this fundamental aspect of a well design application. I think almost everyone is aware of this principle but I know for experience that for many it is not so obvious how we can meet all the details of persistence logic independence.
First let's start with the most known pattern: Data Access Object (DAO). Citing from one design patterns book I have [1]:
Problem: You want to encapsulate data access and manipulation in a separate layer
Forces:
- You want to implement data access mechanisms to access and manipulate data in a persistence storage.
- You want to decouple the persistent storage implementation from the rest of your application.
- You want to provide a uniform data access API for a persistent mechanism to various types of data sources, such as RDBMS, LDAP, OODB, XML repositories, flat files, and so on.
- You want to organize data access logic and encapsulate proprietary features to facilitate maintainability and portability.
The DAO classes will contain all the logic to connect for example to a database and get the needed data from the corresponding tables. One important aspect of this DAO is that any implementation should always avoid to return any persistence proprietary object. For example if someone codes a DAO where the returned object is a ResultSet, the class wouldn't be meeting the point #4. The application would be coupled to the JDBC implementation. That is why in the next UML diagram the returned object from the DAO is a "TransferObject".
We don't have to get into much details of TransferObject pattern but I can say with just having domain objects is enough to ensure decoupling with business and persistence layers.

Having implemented the DAO pattern in our app does not decouple in 100% the business layer from the persistence one. Imagine for example you have this DAO class and the client that consumes it:
package com.foo.dao.jdbc;
class FooDAOJDBCImpl {
public void updateFoo(Foo foo) {
...
}
}
public class FooClient {
void updateChangesInFoo(Foo foo) {
com.foo.dao.jdbc.FooDAOJDBCImpl fooDAOJDBCImpl = new com.foo.dao.jdbc.FooDAOJDBCImpl();
fooDAOJDBCImpl.update(foo);
}
}
Notice that the client needs to instantiate directly the JDBC implementation. Even though it is hidden for the client how the DAO class internally updates the data in the data source, the client still knows that the implementation uses JDBC to persist data. If the JDBC implementation has to be replaced by another one, the client code will have to be updated to use the new DAO class.
To make our design more flexible to such type of possible changes, and also to have our code prepared for unit testing (use of mock DAO classes), we can marry our DAO pattern with the AbstractFactory pattern to have a child named DAOFactory. The DAOFactory class uses reflection (one way to do it) to instantiate the DAO class.

public interface DAO {
}
public interface FooDAO extends DAO {
public void update(Foo foo);
}
package com.foo.dao.jdbc;
public class FooJDBCImpl implements FooDAO {
public void update(Foo foo) {
....
}
}
public class FooClient {
void updateChangesInFoo(Foo foo) {
FooDAO dao = (FooDAO) DAOFactory.getDAO("foo") ;
dao.update(foo);
}
}
It is not until execution time that is known what DAO class will be used to execute the persistence method. The name of the classes can be stored in a properties file. If the implementation of the DAO class is changed, it will be totally transparent to the Client class.
/**
Properties in some file:
foo=com.foo.dao.jdbc.FooDAOJDBCImpl
foo2=com.foo.dao.jdbc.Foo2DAOJDBCImpl
**/
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.util.Properties;
public class DAOFactory {
private static Properties props = new Properties();
private static boolean loadedProperties = false;
private static String propertiesPath;
public static void init(String propertiesPath) {
propertiesPath = path;
}
public static DAOFactory getDAO(String name) {
try {
Class daoClass = Class.forName( getClass( name ) );
return (DAO) daoClass.newInstance();
}
catch (ClassNotFoundException e) {
e.printStackTrace();
return null;
}
catch (Exception e) {
e.printStackTrace();
return null;
}
}
private static String getClass( String propertyName ) {
String className = null;
try {
if ( !loadedProperties ) {
FileInputStream file = new FileInputStream( propertiesPath );
props.load( file );
loadedProperties = true;
}
className = props.getProperty( propertyName, "");
if ( className.length() == 0)
return null;
}
catch ( FileNotFoundException e) {
e.printStackTrace();
}
catch ( IOException e) {
e.printStackTrace();
}
catch (Exception e) {
e.printStackTrace();
}
return className;
}
}
The last design pattern to complete our gang is the Business Object (BO). I'm still learning how to use it correctly, I just realized writing this post that I have some fixes to do in a current implementation I have. But anyways, one of the main purposes of this pattern is to separate the persistence logic from the business logic. Normally in our applications we have a complex conceptual model containing structured, interrelated composite objects. Those complex composite relationships between classes require a lot of logic just to persist. So to avoid mixing these two logic's, an intermediate layer between business logic and data access is created; the BO's layer.
Let's suppose we have a class Foo containing a list of Foo2 objects:
public class Foo {
private List<oo2> foo2s;
private String someAttribute;
}
public class Foo2 {
private String someAttribute;
}
If we want to persist our Foo class, we create two BO classes. The FooBO is the main entry point to save all the composite objects contained inside
Foo2 domain class.
public class FooBO {
public void saveFoo(Foo foo) {
FooDAO fooDAO = (FooDAO) DAOFactory.getDAO("foo") ;
fooDAO.saveBasicFooInfo(foo);
Foo2BO foo2Bo = new Foo2BO();
for (Foo2 foo2 : foo.getFoo2s()) {
foo2Bo.saveFoo2(foo2);
}
}
}
public class Foo2BO {
public void saveFoo2(Foo foo) {
FooDAO2 fooDAO2 = (FooDAO2) DAOFactory.getDAO("foo2") ;
fooDAO2.saveFoo2(foo2);
}
}
There can be different ways to implement any of the 3 patterns described in this post; nothing is written in stone in the programming field. The idea was to provide a quick look on these three main patterns. If anyone has anything interesting to add, comments are well welcome.
[1] Deepak Alur, John Crupi, Dan Malks. "Core J2EE Patterns, Best Practices and Design Strategies", 2003. Pags: 462,463.
Monday, November 5, 2012
A Few File Operations || Building a Synchronizer
Recently in the project I’ve been working in the last couple of months, we had to think in a way to solve the problem of keep updated some local copies of repositories where the originals are located in remote servers. Due to the kind operations we need to run, we couldn’t afford to do them directly in the remote servers. If you are thinking right now, “well duh! Use SVN you dummy” , well, let’s say that our client does not have it and there is no close possibility he will install it for us. We only had access to the share drives where we could read the file systems. That’s all we had.
This kind of operation we required is known (at least that’s how we use it) as directory synchronization. In our case we needed to keep the most updated version as possible of the remote files. The synchronization is very useful when the cost to copy everything is too high.
For example if you have a remote directory with 200GB, you don’t want to copy everything every time you want to update your local copy. It just takes too much time.
I did some research to find a tool that could do what I wanted, and I did find some good ones, but with the only inconvenience that I needed something I could customize to our processes. So I started playing a bit with the java.io.File class and realized that I could program a Synchronizer.
In this post I want to share some useful operations of the File class in light of the problem that my team needed to solve.
Let’s put an example of what the Synchronizer needs to do.
Let’s suppose we have this remote directory:
gsolano_remote
+ 20100514
++ calculations.xls
+ 20100514
++ HelloWorld.java
+ readme.txt
And we have the local copy that need s to be updated:
gsolano_local
+ 20100514
++ calculations.xls
++ deletelater
+ bck-ups
+ readme.txt
+ dir.txt
If we compare the two directories, the local copy would have to execute the next actions (enclosed in parentheses).
gsolano_local
+ 20100514
++ calculations.xls
++ deletelater (remove)
+ bck-ups (remove)
+ readme.txt (update)
+ dir.txt (remove)
+ 20100514 (add)
++ HelloWorld.java (add)
The logic that needs to be coded to run those actions is very simple. First we list the files from source (gsolano_remote) and target (gsolano_local), then we compare them to extract:
+ List of new files to copy from source to target,
+ List of files that need to be updated because they were modified in the source.
+ Files and directories that are no longer present in the source and for instance need to be removed from target.
Once we get these lists we just have to execute the respective copies and deletions. Let’s examine first how to scan files from a directory.
package gsolano;
import java.io.File;
import java.io.IOException;
import java.util.LinkedHashMap;
import java.util.Map;
public class Dir {
/**
* Returns a list of all file paths relative to the provided path.
* @param path
* @return list of relative paths.
*/
public static Map<String, Long> scan(String path) {
Map<String, Long> fileList = new LinkedHashMap<String, Long>();
scanFiles(path.toLowerCase(), path, fileList);
return fileList;
}
/**
* Method for recursively scan.
* @param rootSource
* @param path
* @param fileList
*/
private static void scanFiles(String rootSource, String path, Map<String, Long> fileList) {
File folder = new File(path); // This is the root directory.
// List files from first level of root directory.
File[] listOfFiles = folder.listFiles();
if (listOfFiles.length == 0) {
// Used to keep record of empty folders.
fileList.put(path.toLowerCase().replace(rootSource, "")
+ File.separator + ".", new Long(0));
}
else {
for (int i = 0; i < listOfFiles.length; i++) {
if (listOfFiles[i].isFile()) { // Is it a file?
try {
// Add it to the file list with the last modified date.
fileList.put(listOfFiles[i].getAbsolutePath().toLowerCase()
.replace(rootSource, ""), listOfFiles[i].lastModified());
} catch (Exception e) {
e.printStackTrace();
}
} else if (listOfFiles[i].isDirectory()) { // Is it a directory?
try {
// Recursively call for new found directory.
scanFiles(rootSource, listOfFiles[i].getCanonicalPath(), fileList);
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
}
In this code we start exploring some capabilities of the File class. The first one is the ability to list files from a directory. We simply create an instance of a File class with the path of a directory and then we use the function “listFiles()”.
File folder = new File(path); File[] listOfFiles = folder.listFiles();
Now, this function only gets the files and directories at the first level, it does not retrieve the files of subsequent directories in the next levels; that’s why in the Dir class the file scanning works with a recursively function.
To determine if we need to execute a recursively call, we use the functions “isFile()” and “isDirectory()”. If the file that is read is a directory (sound weird, I agree), then a recursively call is made. If it is a file, then it is added to the list.
In this class we are also using the function “lastModified()” to store the last modified of each of the files scanned. This will be used to determine if the file from source changed causing to have to update the file in the target.
Before jumping to the main class, let’s take a look of the class used to copy files. I modified a bit
a class the I found in the Internet :
package gsolano;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
public class FileCopy {
/**
* Copies one file from the source to specified target.
* @param fromFileName
* @param toFileName
* @param overrideFiles
* @throws IOException
*/
public static void copy(String fromFileName, String toFileName,
boolean overrideFiles) throws IOException {
File toFile = new File(toFileName);
if (toFile.exists() && !overrideFiles) {
return;
}
File fromFile = new File(fromFileName);
if (!fromFile.exists())
throw new IOException("FileCopy: " + "no such source file: "
+ fromFileName);
if (!fromFile.isFile())
throw new IOException("FileCopy: " + "can't copy directory: "
+ fromFileName);
if (!fromFile.canRead())
throw new IOException("FileCopy: " + "source file is unreadable: "
+ fromFileName);
if (toFile.isDirectory()) {
toFile = new File(toFile, fromFile.getName());
}
if (toFile.exists()) {
if (!toFile.canWrite()) {
throw new IOException("FileCopy: "
+ "destination file is unwriteable: " + toFileName);
}
String parent = toFile.getParent();
if (parent == null)
parent = System.getProperty("user.dir");
File dir = new File(parent);
if (!dir.exists())
throw new IOException("FileCopy: "
+ "destination directory doesn't exist: " + parent);
if (dir.isFile())
throw new IOException("FileCopy: "
+ "destination is not a directory: " + parent);
if (!dir.canWrite())
throw new IOException("FileCopy: "
+ "destination directory is unwriteable: " + parent);
} else {
// Create directory structure.
new File(toFile.getParent()).mkdirs();
}
createCopy(toFile, fromFile);
}
/**
* Writes the copy from source to target.
* @param toFile
* @param fromFile
* @throws FileNotFoundException
* @throws IOException
*/
private static void createCopy(File toFile, File fromFile)
throws FileNotFoundException, IOException {
FileInputStream from = null;
FileOutputStream to = null;
try {
from = new FileInputStream(fromFile);
to = new FileOutputStream(toFile);
byte[] buffer = new byte[4096];
int bytesRead;
while ((bytesRead = from.read(buffer)) != -1)
to.write(buffer, 0, bytesRead); // write
} finally {
if (from != null)
try {
from.close();
} catch (IOException e) {
;
}
if (to != null)
try {
to.close();
toFile.setLastModified(fromFile.lastModified());
} catch (IOException e) {
;
}
}
}
}
The FileCopy uses six more functions of the java File class:
1.“exists()”: used to double-check if the source file really exists.
2.“canRead()”: used to determine if the source file can be read.
3.“canWrite():”: used to determine if target file can be overwrite. This is used in the cases where we need to update the file.
4."getParent()”: to get the parent path of the file.
5.“mkDirs()”: I have to say this is my favorite one; it creates all the directory hierarchy of the file’s path.
6.“setLastModifiedDate()”: when we finish copying the file in the target directory, we wanted to leave the same modified date of the source.
To conclude with the Synchronizer class we just have to see one more function and a constant:
+ “delete()”: deletes the file or directory.
+ “File.separator”: system dependant character used to separate directories in a path. In this example the separator is the back-slash (“\”).
The Synchronizer class do all the basic steps required to synchronize the two directories. The list of copies and deletions are calculated with simple comparisons of collections (sets and maps).
I would like to test if this works in other OS but I'm kind of lazy for that. Theoretically it does work ;).
package gsolano;
import java.io.File;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Set;
/**
*
* Class used to synchronize two directories. One directory (source)
* is used as base of another directory (target).
* The class determines the operations required to leave the target
* with the same structure as the source.
*
* @author gsolano
*
*/
public class Synchronizer {
public static void main(String[] args) {
Synchronizer.run("c:\\gsolano_remote\\", "c:\\gsolano_local\\");
}
public static void run(String source, String target) {
System.out.println("Scanning source directory...");
Map<String, Long> sourceFiles = Dir.scan(source);
System.out.println("[DONE]");
System.out.println("Scanning target directory...");
Map<String, Long> targetFiles = Dir.scan(target);
System.out.println("[DONE]");
List<String> newFilesToCopy = getNewFilesToCopy(sourceFiles.keySet(), targetFiles.keySet());
System.out.println("Total new files to copy: " + newFilesToCopy.size());
List<String> filesToUpdate = getFilesToUpdate(sourceFiles, targetFiles);
System.out.println("Total files to update: " + filesToUpdate.size());
List<String> filesToRemove = getFilesToRemove(sourceFiles.keySet(), targetFiles.keySet());
System.out.println("Total files to remove: " + filesToRemove.size());
List<String> dirsToRemove = getDirectoriesToRemove(sourceFiles.keySet(), targetFiles.keySet());
System.out.println("Total dirs to remove: " + dirsToRemove.size());
System.out.println("Copying new files...");
for(String fileToCopy : newFilesToCopy) {
try {
FileCopy.copy(source + File.separator + fileToCopy,
target + File.separator + fileToCopy, false);
} catch (IOException e) {
System.out.println("Couldn't copy file: " + fileToCopy + "(" + e.getMessage() + ")");
}
}
System.out.println("Updating files...");
for(String fileToUpdate : filesToUpdate) {
try {
FileCopy.copy(source + File.separator + fileToUpdate,
target + File.separator +fileToUpdate, true);
} catch (IOException e) {
System.out.println("Couldn't copy file: " + fileToUpdate + "(" + e.getMessage() + ")");
}
}
System.out.println("Removing files from target...");
for(String fileToRemove : filesToRemove) {
new File(target + fileToRemove).delete();
}
System.out.println("Removing directories from target...");
for(String dirToRemove : dirsToRemove) {
new File(target + dirToRemove).delete();
}
}
/**
* Return the list of directories to be removed. A directory is removed
* if it is present in the target but not in the source.
* @param sourceFiles
* @param targetFiles
* @return
*/
private static List<String> getDirectoriesToRemove(Set<String> sourceFiles,
Set<String> targetFiles) {
List<String> directoriesToRemove = new ArrayList<String>();
Set<String> sourceDirs = buildDirectorySet(sourceFiles);
Set<String> targetDirs = buildDirectorySet(targetFiles);
for(String dir : targetDirs) {
if (!sourceDirs.contains(dir)) {
directoriesToRemove.add(dir);
}
}
return directoriesToRemove;
}
/**
* Return the list of files to be removed.
* A file is removed if it is present in the target
* but not in the source.
* @param sourceFiles
* @param targetFiles
* @return
*/
private static List<String> getFilesToRemove(Set<String> sourceFiles,
Set<String> targetFiles) {
List<String> filesToRemove = new ArrayList<String>();
for (String filePath : targetFiles) {
if (!sourceFiles.contains(filePath) &&
!filePath.endsWith(File.separator + ".")) {
filesToRemove.add(filePath);
}
}
return filesToRemove;
}
/**
* Gets the the list of files missing in the target directory.
* @param sourceFiles
* @param targetFiles
* @return
*/
private static List<String> getNewFilesToCopy(Set<String> sourceFiles,
Set<String> targetFiles) {
List<String> filesToCopy = new ArrayList<String>();
for (String filePath : sourceFiles) {
if (!targetFiles.contains(filePath)) {
if(!filePath.endsWith(File.separator + ".")) {
filesToCopy.add(filePath);
}
}
}
return filesToCopy;
}
/**
* Gets the list of files to be updated according to the last
* modified date.
* @param sourceFiles
* @param targetFiles
* @return
*/
private static List<String> getFilesToUpdate(Map<String, Long> sourceFiles,
Map<String, Long> targetFiles) {
List<String> filesToUpdate = new ArrayList<String>();
Iterator<Map.Entry<String, Long>> it = sourceFiles.entrySet().iterator();
while (it.hasNext()) {
Map.Entry<String, Long> pairs = it.next();
String filePath = pairs.getKey();
if (targetFiles.containsKey(filePath) &&
!filePath.endsWith(File.separator + ".")) {
long sourceModifiedDate = sourceFiles.get(filePath);
long targetModifiedDate = targetFiles.get(filePath);
if(sourceModifiedDate != targetModifiedDate) {
filesToUpdate.add(filePath);
}
}
}
return filesToUpdate;
}
/**
* Returns the set of directories contained in the set of file paths.
* @param files
* @return Set of directories representing the directory structure.
*/
private static Set<String> buildDirectorySet(Set<String> files) {
Set<String> directories = new HashSet<String>();
for(String filePath : files) {
if (filePath.contains(File.separator)) {
directories.add(filePath.substring(0,
filePath.lastIndexOf(File.separator)));
}
}
return directories;
}
}
Output:
 ;
;
Sunday, November 4, 2012
Android: Rock, Paper, Scissors
I'm giving my first baby steps in the Android development world. In this simple application I exemplify the use of:

This is the layout XML:

- Buttons
- Click events
- Image Views
- Alert dialogs
The application is a simple game of "Rock, Paper, Scissors". User clicks on an image button according to the selection, and immediately the Android makes a random selection. According to the universal very well known rules of this game, an alert dialog is shown with the game result.
So here's the basic layout of the game. The two interrogation images are for displaying the two selections. The three images below are for the user to select an option.
This is the layout XML:
<RelativeLayout xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:tools="http://schemas.android.com/tools"
android:layout_width="match_parent"
android:layout_height="match_parent" >
<TextView
android:id="@+id/textView1"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:layout_alignParentTop="true"
android:layout_centerHorizontal="true"
android:layout_marginTop="20dp"
android:padding="@dimen/padding_medium"
android:text="Rock, Paper, Scissors!"
tools:context=".RockPaperScissors" />
<Button
android:id="@+id/buttonRock"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:layout_alignParentBottom="true"
android:layout_marginBottom="147dp"
android:layout_marginRight="20dp"
android:layout_toLeftOf="@+id/textView1"
android:background="@drawable/rock_small" />
<Button
android:id="@+id/buttonPaper"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:layout_alignBaseline="@+id/buttonRock"
android:layout_alignBottom="@+id/buttonRock"
android:layout_centerHorizontal="true"
android:background="@drawable/paper_small" />
<Button
android:id="@+id/buttonScissors"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:layout_alignBaseline="@+id/buttonPaper"
android:layout_alignBottom="@+id/buttonPaper"
android:layout_marginLeft="23dp"
android:layout_toRightOf="@+id/textView1"
android:background="@drawable/scissors_small" />
<ImageView
android:id="@+id/imageViewAnswerUser"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:layout_below="@+id/textView1"
android:layout_marginTop="26dp"
android:layout_toLeftOf="@+id/buttonPaper"
android:src="@drawable/question" />
<ImageView
android:id="@+id/ImageViewAnswerAndroid"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:layout_alignRight="@+id/buttonScissors"
android:layout_alignTop="@+id/imageViewAnswerUser"
android:src="@drawable/question" />
<ImageButton
android:id="@+id/imageButtonHome"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:layout_alignRight="@+id/buttonPaper"
android:layout_below="@+id/buttonPaper"
android:layout_marginTop="38dp"
android:src="@drawable/home" />
</RelativeLayout>
This is the code for the activity:
package com.example.mytoolbox;
import android.app.Activity;
import android.app.AlertDialog;
import android.content.DialogInterface;
import android.content.Intent;
import android.os.Bundle;
import android.view.Menu;
import android.view.View;
import android.view.View.OnClickListener;
import android.widget.Button;
import android.widget.ImageButton;
import android.widget.ImageView;
public class RockPaperScissors extends Activity implements OnClickListener {
public enum Option {
ROCK, PAPER, SCISSORS
}
public enum Result {
WIN, LOSS, DRAW
}
private Option userSelection;
private Result gameResult;
@Override
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_rock_paper_scissors);
Button buttonRock = (Button) findViewById(R.id.buttonRock);
Button buttonpaper = (Button) findViewById(R.id.buttonPaper);
Button buttonScissors = (Button) findViewById(R.id.buttonScissors);
ImageButton buttonHome = (ImageButton) findViewById(R.id.imageButtonHome);
// Set click listening event for all buttons.
buttonRock.setOnClickListener(this);
buttonpaper.setOnClickListener(this);
buttonScissors.setOnClickListener(this);
buttonHome.setOnClickListener(this);
}
@Override
public boolean onCreateOptionsMenu(Menu menu) {
getMenuInflater().inflate(R.menu.activity_rock_paper_scissors, menu);
return true;
}
@Override
public void onClick(View v) {
ImageView imageView = (ImageView) findViewById(R.id.imageViewAnswerUser);
boolean play = true;
switch (v.getId()) {
case R.id.buttonRock:
userSelection = Option.ROCK;
imageView.setImageResource(R.drawable.rock);
break;
case R.id.buttonPaper:
userSelection = Option.PAPER;
imageView.setImageResource(R.drawable.paper);
break;
case R.id.buttonScissors:
userSelection = Option.SCISSORS;
imageView.setImageResource(R.drawable.scissors);
break;
case R.id.imageButtonHome:
startActivity(new Intent(RockPaperScissors.this, ChooseActivity.class)); // To go home.
play = false;
break;
}
if(play) {
play();
showResults();
}
}
private void showResults() {
AlertDialog.Builder builder = new AlertDialog.Builder(RockPaperScissors.this);
builder.setCancelable(false);
builder.setPositiveButton("OK", new DialogInterface.OnClickListener() {
@Override
public void onClick(DialogInterface dialog, int which) {
// Do nothing
}
});
// Sets the right message according to result.
if(gameResult == Result.LOSS) {
builder.setMessage("You Loose!");
} else if(gameResult == Result.WIN) {
builder.setMessage("You Win!");
} else if(gameResult == Result.DRAW) {
builder.setMessage("It's a draw!");
}
AlertDialog alert = builder.create();
alert.show();
}
private void play() {
// Generates a random play.
int rand = ((int)(Math.random() * 10)) % 3;
Option androidSelection = null;
ImageView imageView = (ImageView) findViewById(R.id.ImageViewAnswerAndroid);
// Sets the right image according to random selection.
switch (rand) {
case 0:
androidSelection = Option.ROCK;
imageView.setImageResource(R.drawable.rock);
break;
case 1:
androidSelection = Option.PAPER;
imageView.setImageResource(R.drawable.paper);
break;
case 2:
androidSelection = Option.SCISSORS;
imageView.setImageResource(R.drawable.scissors);
break;
}
// Determine game result according to user selection and Android selection.
if(androidSelection == userSelection) {
gameResult = Result.DRAW;
}
else if(androidSelection == Option.ROCK && userSelection == Option.SCISSORS) {
gameResult = Result.LOSS;
}
else if(androidSelection == Option.PAPER && userSelection == Option.ROCK) {
gameResult = Result.LOSS;
}
else if(androidSelection == Option.SCISSORS && userSelection == Option.PAPER) {
gameResult = Result.LOSS;
} else {
gameResult = Result.WIN;
}
}
}
Running app:

Friday, November 2, 2012
Using Observer Pattern to track progress while loading a page
Have you ever been in a site where there is a heavy process that takes a long time in finishing? If the web page is not user friendly designed, you may end it up with an annoying forever loading page.
If we want to avoid this feeling of slowness in our pages, we should consider adding a progress indicator in the page to show how much is left until process is finished. To accomplish this we can take advantage of the Observer pattern.
To do this we need to run the process asynchronously, or in other words, running it as a different thread. The next diagram shows how the long process is contained in Thread class.

The following class is going to emulate a long process by taking various naps.
package com.gsolano.longprocess
import java.util.Observable;
/**
* Class with an observable mock long progress.
* @author gsolano
*
*/
public class LongProcess extends Observable {
/**
* Keeps the progress of the process.
*/
protected Float progress;
/**
* Simulates a long process.
*/
public void start() {
int n =10;
for (int i=0;i <= n; i++) {
progress = (float)i/(float)n * 100; // Calculates progress.
try {
Thread.currentThread();
Thread.sleep(2000);
this.setChanged();
this.notifyObservers(progress);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
The progress of this class is calculated in every iteration, notifying also the observers with the change in the progress. The next class will observe the LongProcess class.
package com.gsolano.longprocess;
import java.util.Observable;
import java.util.Observer;
/**
* Observer class
*
* @author gsolano
*/
public class LongProcessObserver implements Observer{
protected Float progress;
/**
* Tracks the progress of the long process.
* @return
*/
public Float getProgress() {
return progress;
}
public void update(Observable o, Object arg) {
progress = (Float) arg;
}
}
To complete the diagram shown before, we need to create a class extending from Thread to wrap the LongProcess and be able to launch in a separate thread.
/**
*
* Class to run a LongProcess in a separate thread.
*
* @author gsolano
*
*/
public class LongProcessThread extends Thread {
private LongProcess longProcess;
public LongProcess getLongProcess() {
return longProcess;
}
public void setLongProcess(LongProcess longProcess) {
this.longProcess = longProcess;
}
@Override
public void run() {
if(longProcess != null) {
longProcess.start();
}
}
}
Now, let’s jump to the web application side. In the next struts action class we handle two events:
1.Start the long process:
a .Long process is created.
b. Observer is added to the long process.
c. Long process is run in a separate thread.
d. Observer is saved in session variable.
2.Send an update on the progress of the long process
a. Observer is retrieved from session.
b. Progress value is taken from observer and written to response.
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.apache.struts.action.Action;
import org.apache.struts.action.ActionForm;
import org.apache.struts.action.ActionForward;
import org.apache.struts.action.ActionMapping;
public class FooProgressAction extends Action{
@Override
public ActionForward execute(ActionMapping mapping, ActionForm form,
HttpServletRequest request, HttpServletResponse response)
throws Exception {
String action = request.getParameter("action");
if(action != null) {
if(action.equalsIgnoreCase("progress")) { // If action is ajax request to get progress.
// Get the observer.
LongProcessObserver longProcessObserver = (LongProcessObserver)
request.getSession().getAttribute("observer");
if(longProcessObserver != null) {
// Get the progress from the observer.
Float progress = longProcessObserver.getProgress();
if(progress != null) {
// Send the progress to the page.
response.getWriter().write(progress.toString());
}
return null;
}
} else if(action.equalsIgnoreCase("start")) { // Did someone click the start button?
launchLongProcess(request);
}
}
return mapping.findForward("success");
}
private void launchLongProcess(HttpServletRequest request) {
LongProcess longProcess = new LongProcess();
LongProcessObserver observer = new LongProcessObserver();
// Add the observer to the long process.
longProcess.addObserver(observer);
// Launch long process in a thread.
LongProcessThread longProcessThread = new LongProcessThread();
longProcessThread.setLongProcess(longProcess);
longProcessThread.start();
// Keep the observer in session.
request.getSession().setAttribute("observer", observer);
// Send a flag indicating that party just started!
request.setAttribute("processStarted", true);
}
}
In the client side we just need some logic to start the Ajax cycle to ask for progress update until it reaches the 100%.
<%@ taglib uri="/WEB-INF/tld/c.tld" prefix="c" %>
<html>
<head>
<script language="Javascript">
var seconds = 1;
var run = false;
var ajaxURL;
function checkProgress(url) {
if(typeof url != 'undefined') {
ajaxURL = url;
}
var xmlHttp;
try {
xmlHttp = new XMLHttpRequest(); // Firefox, Opera 8.0+, Safari
} catch (e) {
try {
xmlHttp = new ActiveXObject("Msxml2.XMLHTTP"); // Internet Explorer
} catch (e) {
try {
xmlHttp = new ActiveXObject("Microsoft.XMLHTTP");
} catch (e) {
alert("Ajax not supported");
return false;
}
}
}
xmlHttp.onreadystatechange = function() {
if (xmlHttp.readyState == 4 ) {
var progress = xmlHttp.responseText;
if(progress == 100.0) {
document.getElementById('progress').innerHTML = "Finished!!";
return;
}else {
if(progress) {
document.getElementById('progress').innerHTML = progress + "%";
}
setTimeout('checkProgress()', seconds * 1000);
}
}
};
xmlHttp.open("GET", ajaxURL, true);
xmlHttp.send(null);
}
</script>
</head>
<body>
<div style="position: absolute; left:40%; text-align:center; border: 1px solid; margin: 20px; padding:20px; width: 150px;">
<form action="${pageContext.request.contextPath}/longProcess.do">
<input type="hidden" name="action" value="start" />
<input type="submit" value="Start!" />
</form>
<div id="progress"></div>
<c:if test="${not empty processStarted}">
<script language="Javascript">
setTimeout('checkProgress(\'${pageContext.request.contextPath}/longProcess.do?action=progress\')', 1000);
</script>
</c:if>
</div>
</body>
</html>
Result:

To be, or not to be ...
To be, or not to be ... a manager, that is the question. Remember the first time you coded a Hello World application. If the programming muse touched you at that moment, you felt like you wanted to do this for the rest of your life. Or maybe not, but at least you found some level of vocation that motivated you in some fashion to keep improving in the software development world.
A short comment:
- I'm using the software development area as the most typical applied areas of our computer scientist market. Evidently, not everyone has to like programming. There are other valid career paths where a person can find his vocation. Nonetheless, I want to develop a point that can be applied to any computer technical specialization. -
You start your first job as a programmer. If your muse hasn't abandoned you yet, getting better is your goal. You learn from your co-workers, keep updated in the latest technologies and do all the necessary to improve your technical skills.
Now, becoming a better programmer is not an altruist activity. Even though for some of us programming is like playing intellectual games; solving puzzles we may say (I know some friends that find it relaxing). We don't do this for free. We chose a career with the expectation of finding profitable opportunities, whether we are employed or want to start our own business.
That is the general case of almost every career. Our capitalist impulse moves us to do better in whatever we do for living. And there is nothing wrong with that, we all have responsibilities and want to increase our life quality. Therefore, there's a strong correlation of our professional growth with the increase of our retributions.
But if you have some years working in a software company, you know there's a point where your leadership skills can take you in another direction, a little or big detour from the technical path. It can start by becoming the technical lead of you team. At this point you still have the best of the two worlds. You can still be involved in the technical aspects of the project, and at the same time sharp those soft skills to handle a team and resources. But once you have tasted the sweetness of the management path, it becomes some difficult turning back.
I want to clarify that I don't see any wrong with taking the management career path. A lot of people had envisioned their careers having in mind that the programming or technical work is just a step that they have to take in order to ascend in their professional wroth to become managers of their respective fields. That is fine. In order to be a good professional, you don't have to necessary be a specialist in a technical area. What I do find wrong is the limitations we have in the local market to take a path that some of us find attracting, but that unfortunately, due to our need$, most of the time we are tempted to take the easy path.
Why do I say management is the easy path? I can give you a list of reasons (take in mind I speak in general terms):
Perhaps, I could be wrong at some level on any of my appreciations, but one thing that backs me up is the general opinion of the programmer's community. Grab a group of programmers and ask them how they feel about the recognition they receive compared to the management positions, and most of them will tell you that is very unbalanced. I know this is also an issue in the old continent as I once heard in a podcast from Java Hispano (founded by Spain computer scientists), where very experienced people from this organization who participated in a JavaOne conference, described to the listeners how much they were amazed (jaws touching floor), when they asked, for curiosity, how much a programmer was paid in very important software companies that were participating in the conference. These companies even highlighted the point that their programmers were better paid than those in the management positions.
I don't pretend just to be whining about our “pitiful” situation. I just wanted to do some reflection and come with some ideas. So returning back to my initial statement. What do we do when we feel like we had reached a point where we cannot go any further in our growth inside a company, without abandoning the technical area?

Some ideas:
I suggest not rushing in becoming a manager with a fancy office. Is that something hard?

A short comment:
- I'm using the software development area as the most typical applied areas of our computer scientist market. Evidently, not everyone has to like programming. There are other valid career paths where a person can find his vocation. Nonetheless, I want to develop a point that can be applied to any computer technical specialization. -
You start your first job as a programmer. If your muse hasn't abandoned you yet, getting better is your goal. You learn from your co-workers, keep updated in the latest technologies and do all the necessary to improve your technical skills.
Now, becoming a better programmer is not an altruist activity. Even though for some of us programming is like playing intellectual games; solving puzzles we may say (I know some friends that find it relaxing). We don't do this for free. We chose a career with the expectation of finding profitable opportunities, whether we are employed or want to start our own business.
That is the general case of almost every career. Our capitalist impulse moves us to do better in whatever we do for living. And there is nothing wrong with that, we all have responsibilities and want to increase our life quality. Therefore, there's a strong correlation of our professional growth with the increase of our retributions.
But if you have some years working in a software company, you know there's a point where your leadership skills can take you in another direction, a little or big detour from the technical path. It can start by becoming the technical lead of you team. At this point you still have the best of the two worlds. You can still be involved in the technical aspects of the project, and at the same time sharp those soft skills to handle a team and resources. But once you have tasted the sweetness of the management path, it becomes some difficult turning back.
I want to clarify that I don't see any wrong with taking the management career path. A lot of people had envisioned their careers having in mind that the programming or technical work is just a step that they have to take in order to ascend in their professional wroth to become managers of their respective fields. That is fine. In order to be a good professional, you don't have to necessary be a specialist in a technical area. What I do find wrong is the limitations we have in the local market to take a path that some of us find attracting, but that unfortunately, due to our need$, most of the time we are tempted to take the easy path.
Why do I say management is the easy path? I can give you a list of reasons (take in mind I speak in general terms):
- Most of software related companies favor this career path by offering more ascent opportunities with higher salaries than technical positions.
- Although it depends of the kind of work; and mostly personal attitude. A manager can become a lazy person and still accomplish his basic activities. Assign tasks, supervise the daily work, create a presentation, attend meetings, etc.
- The management path has more visibility for the upper management. The technical people is seem as merely ants or engine parts that can relatively easy be replaced. By the other hand, when someone important in high levels of management leaves the company, this is perceived as an important new or great gossip (depending on how this is handled by the company).
Perhaps, I could be wrong at some level on any of my appreciations, but one thing that backs me up is the general opinion of the programmer's community. Grab a group of programmers and ask them how they feel about the recognition they receive compared to the management positions, and most of them will tell you that is very unbalanced. I know this is also an issue in the old continent as I once heard in a podcast from Java Hispano (founded by Spain computer scientists), where very experienced people from this organization who participated in a JavaOne conference, described to the listeners how much they were amazed (jaws touching floor), when they asked, for curiosity, how much a programmer was paid in very important software companies that were participating in the conference. These companies even highlighted the point that their programmers were better paid than those in the management positions.
I don't pretend just to be whining about our “pitiful” situation. I just wanted to do some reflection and come with some ideas. So returning back to my initial statement. What do we do when we feel like we had reached a point where we cannot go any further in our growth inside a company, without abandoning the technical area?
Some ideas:
- Be a rock star. That is, become a super technical guy, a super saya of the programming. When you shine is improbable not to be noticed.
- Be a revolutionary. Try to change things in your company by becoming a leader and defender of the community.
- Join forces. A bit dangerous! Sometimes is hard to serve two masters. But I guess with discipline you can take the management side and at the same time still be involve with the tech world. Maybe do the second outside the office.
- Evaluate moving to another company. A careful-well-thought-required move. If you go to an interview, make sure to ask about the career paths offered in the company.
I suggest not rushing in becoming a manager with a fancy office. Is that something hard?
Thursday, November 1, 2012
Determining redirects when accessing an URL
Here’s a basic example on how to determine when opening a HTTP request, if the URL redirects to another one. The function of this class gets the HTTP response code from the HTTP connection, and if the code is any of the ones associated with redirection: 301/302/303, it obtains the final destination from the "Location" header.
Result:
import java.net.HttpURLConnection;
import java.net.URL;
public class URLUtils {
/**
* Prints the redirect URL for the provided input URL (if it applies).
* @param url
*/
public static void printRedirect(String url) {
try {
URL urlToPing = new URL(url);
HttpURLConnection urlConn = (HttpURLConnection) urlToPing.openConnection();
// Needed to check if it is a redirect.
urlConn.setInstanceFollowRedirects(false);
// It's any of these response codes: 301/302/303
if (urlConn.getResponseCode() == HttpURLConnection.HTTP_MOVED_PERM
|| urlConn.getResponseCode() == HttpURLConnection.HTTP_MOVED_TEMP
|| urlConn.getResponseCode() == HttpURLConnection.HTTP_SEE_OTHER) {
System.out.println("URL <" + url + "> redirects to: <" + urlConn.getHeaderField("Location") + ">, Response Code: " + +urlConn.getResponseCode());
} else {
System.out.println("URL <" + url + "> has no redirect, Response Code: " + urlConn.getResponseCode());
}
} catch (Exception e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
URLUtils.printRedirect("http://www.google.com");
URLUtils.printRedirect("http://www.crjug.org");
}
}
Result:
URL <http://www.google.com> redirects to: <http://www.google.co.cr/>, Response Code: 302 URL <http://www.crjug.org> has no redirect, Response Code: 200
Wednesday, October 31, 2012
Java: Parsing an HTML page
I wanted to share an example code showing how to parse an HTML page using the open library HTML Parser. I used this library in the past for a project where we required to extract all links of a site, and now I’m about to use it again for a project where we need to validate certain HTML coding rules. This library is simple and very straightforward to use.
So let’s assume we need to find all the absolute URL’s referenced in a page. First, we create our parser class:
import java.io.IOException;
import java.net.URL;
import org.htmlparser.Node;
import org.htmlparser.Tag;
import org.htmlparser.lexer.Lexer;
import org.htmlparser.util.ParserException;
/**
* Parses the HTML code of the page specified by it's URL.
* @author gabriel.solano
*
*/
public class URLHTMLParser {
/*
* Tag handler that will be used to process the tags.
* (This could be improved by implementing an observer
* pattern to be able to add more than one TagHandler)
*/
private TagHandler tagHandler;
/**
* Constructor.
* @param tagHandler
*/
public URLHTMLParser(TagHandler tagHandler) {
this.tagHandler = tagHandler;
}
/**
* Scans the specified URL.
* @param url
* @throws ParserException
* @throws IOException
*/
public void scanURL(URL url) throws ParserException, IOException {
Lexer lexer = new Lexer(url.openConnection());
extractHTMLNodes(lexer);
}
/**
* Extracts the HTML nodes and lets the TagHandler to do something
* with the tags.
* @param lexer
* @throws ParserException
*/
private void extractHTMLNodes(Lexer lexer) throws ParserException {
Node node;
while (null != (node = lexer.nextNode(false))) {
if (node instanceof Tag) {
Tag tag = (Tag) node;
tagHandler.handleTag(tag);
}
}
}
}
As you can see, the last function of this class is in charge of moving across the HTML nodes. I just let the TagHandler class to do whatever is required with the tag.
This is the interface for the TagHandler:
import org.htmlparser.Tag;
/**
* Defines the interface for a TagHandler.
* @author gabriel.solano
*
*/
public interface TagHandler {
/**
* Handles the process of an HTML tag.
* @param tag
*/
public void handleTag(Tag tag);
}
And here’s my implementation to handle anchor tags:
import java.util.HashSet;
import java.util.Set;
import org.htmlparser.Tag;
/**
* Handles the event when an anchor tag is found while parsing
* HTML code of a page.
* This class has a functionality to count all absolute URLs
* found in the parsing process.
* @author gabriel.solano
*
*/
public class AnchorTagHandler implements TagHandler{
private Set<String> absoluteURLs; // All URLs found.
/**
* Constructor.
*/
public AnchorTagHandler() {
absoluteURLs = new HashSet<String>();
}
/**
* Gets the found absolute URLs.
* The collection is filled only during the scanning process
* of an HTML page.
* @return
*/
public Set<String> getAbsoluteURLs() {
return absoluteURLs;
}
/**
* Handles the tag only if it is an anchor tag.
*/
public void handleTag(Tag tag) {
if (tag.getTagName().equalsIgnoreCase("a")) {
// Process only if it's an anchor tag.
processTag(tag);
}
}
/**
* Processes the anchor tag. In this case
* adds all absolute URL's found.
* @param tag
*/
private void processTag(Tag tag) {
String href = tag.getAttribute("href");
if (href != null) {
href = href.toLowerCase();
if (href.startsWith("http://") || href.startsWith("https://")) {
// Add all URLs with HTTP protocol.
absoluteURLs.add(href);
}
}
}
}
The “processTag” function simply extracts the “href” attribute and verifies if it is an absolute URL.
Finally we just create a main class to run the code:
import java.net.URL;
import java.util.Set;
public class FindAbsoluteURLs {
public static void main(String[] args) {
AnchorTagHandler anchorTagHandler = new AnchorTagHandler();
URLHTMLParser htmlParser = new URLHTMLParser(anchorTagHandler);
try {
htmlParser.scanURL(new URL("http://www.crjug.org/"));
Set<String> urls = anchorTagHandler.getAbsoluteURLs();
for(String url : urls) {
System.out.println(url);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
Here’s the maven dependency in case you need to use this helpful library:
<java> <dependency> <groupId>org.htmlparser</groupId> <artifactId>htmlparser</artifactId> <version>1.6</version> </dependency> </java>
Monday, October 22, 2012
Not afraid of looking uncool
Sometimes I feel like software development world behave in certain way like fashion mode. I don’t say it because I think it is completely subject of trivial conditions like the influence of a pop star over young teenagers, but in small scale, most popular rock star frameworks tend to monopolize software engineers with recipes, sometimes to the point of thinking that anything distinct from the recipe is out fashion.
Frameworks like Struts, Spring or Hibernate are excellent tools for a lot of development efforts. The problem I think starts when a developer sets his mind to think that all projects should be implemented with the standard “fits all” recipe he uses. If someone else suggests to do something different, or just tells in a friendly conversation that he is using a different approach in an application, the framework recipe guy could look at him as the “uncool” or even mock him as the dinosaur of the team.
I've been watching the lectures from the recent Java Zone 2011 conference, and two short presentations caught my attention for their braveness to questions the “status-quo”. One exposes a different approach for dependency injection:
Dependency injection when you only have one dependency from JavaZone on Vimeo.
And the other one, which is the one that I particularly enjoy the most, is the one from this young lady where she stands firmly, and with good arguments, why she doeen’t like Hibernate.
Hibernate should be to programmers what cake mixes are to bakers: beneath their dignity. from JavaZone on Vimeo.
I’m not taking sides on these two presentations, I must confess that I need more experience to have a more informed position on the specific topics, but I truly admire these two fella for showing their out of the box approach on software development. Innovation comes frequently from setting apart from the rest.
We have a lot to learn as still young developers, and we should always be receptive to new ideas in this always changing business that is the software development world. Some ideas could be crap, but we need to have the humbleness to examine all of them to make a rational judgment on why we discard it. Let’s not be fanatic just because everyone uses a specific tool.
Frameworks like Struts, Spring or Hibernate are excellent tools for a lot of development efforts. The problem I think starts when a developer sets his mind to think that all projects should be implemented with the standard “fits all” recipe he uses. If someone else suggests to do something different, or just tells in a friendly conversation that he is using a different approach in an application, the framework recipe guy could look at him as the “uncool” or even mock him as the dinosaur of the team.
I've been watching the lectures from the recent Java Zone 2011 conference, and two short presentations caught my attention for their braveness to questions the “status-quo”. One exposes a different approach for dependency injection:
Dependency injection when you only have one dependency from JavaZone on Vimeo.
And the other one, which is the one that I particularly enjoy the most, is the one from this young lady where she stands firmly, and with good arguments, why she doeen’t like Hibernate.
Hibernate should be to programmers what cake mixes are to bakers: beneath their dignity. from JavaZone on Vimeo.
I’m not taking sides on these two presentations, I must confess that I need more experience to have a more informed position on the specific topics, but I truly admire these two fella for showing their out of the box approach on software development. Innovation comes frequently from setting apart from the rest.
We have a lot to learn as still young developers, and we should always be receptive to new ideas in this always changing business that is the software development world. Some ideas could be crap, but we need to have the humbleness to examine all of them to make a rational judgment on why we discard it. Let’s not be fanatic just because everyone uses a specific tool.
Subscribe to:
Posts (Atom)